OpenAI przyznaje, że omijanie tzw. halucynacji jest „matematycznie niemożliwe”
OpenAI, który jest odpowiedzialny za ChatGPT, w jednej z najnowszych prac naukowych przyznało, że ograniczenia matematyczne uniemożliwiają całkowite rozwiązanie problemu związanego z tzw. halucynacjami dużych modeli językowych.
W kontekście modeli sztucznej inteligencji, „halucynacja” jest przypadkiem, gdy na podstawie modelu generowane są odpowiedzi, które są fałszywe, ale wciąż brzmią one wystarczająco naturalnie.
W pracy naukowej datowanej na 4 września 2025 roku, autorzy piszą:
Podobnie jak uczniowie zmagający się z trudnymi pytaniami na sprawdzianach, duże modele językowe czasami generują naturalnie brzmiące wypowiedzi, które nie są prawdziwe, zamiast „przyznać”, że nie mają wiedzy na dany temat.
Oprócz własnych modeli językowych, naukowcy pracujący dla OpenAI potwierdzili swoje przypuszczenia także wobec konkurencyjnych modeli językowych — tych spod szyldu chińskiego DeepSeeka, czy też modeli LLaMa od Mety albo Claude Sonnet.
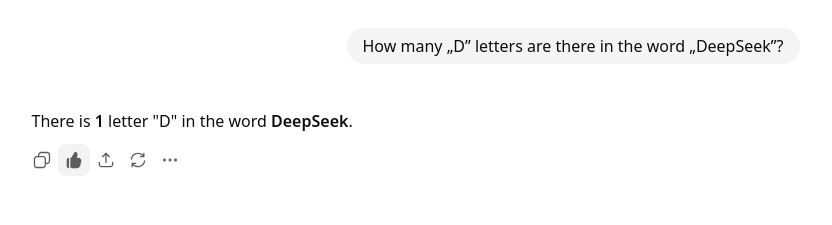
Dla przykładu, proste pytanie brzmiące „ile liter «D» znajduje się w słowie DeepSeek” w przypadku DeepSeeka zwróciło odpowiedź, że „dwie”, z kolei modele Mety czy Claude odpowiadały, że aż „sześć” czy „siedem” — zgodnie z obserwacjami autorów pracy naukowej.
Według naszych pobieżnych testów jedynie model GPT-5 dostępny za pomocą wyszukiwarki DuckDuckGo zdołał odpowiedzieć poprawnie na pytanie — wcześniejsza wersja, GPT-4o mini czy konkurencyjny Claude 3.5 Haiku odpowiadały, że w słowie znajdowały się „dwie” litery.


Model podstawowy dostępny poprzez serwis ChatGPT również odpowiedział bezbłędnie.
Choć najnowsza wersja modelu GPT — oznaczona numerem 5 — zgodnie z zapewnieniami autorów „halucynuje w znacznie mniejszym stopniu”, tak „wciąż mają one miejsce”.
„Takie rzeczy mają miejsce w nawet najlepszych modelach i powodują stratę zaufania do sztucznej inteligencji” — możemy przeczytać w krótkim opisie dokumentu.
Źródła
Zdjęcie tytułowe zostało zrobione przez Jerneja Furmana i jest ono dostępne na Wikimedia Commons na licencji Creative Commons BY 2.0 Generic. Treść artykułu powstała na podstawie następujących źródeł tekstowych i/lub audiowizualnych:
- OpenAI admits AI hallucinations are mathematically inevitable, not just engineering flaws, opublikowany w serwisie computerworld.com przez Gyanę Swain w dniu 18.09.2025
- Why Language Models Hallucinate, numer DOI 2509.04664, datowane na 4.09.2025
Komentarze (0)
Nie ma żadnych komentarzy pod tym wpisem.
Preferuj: